-
[논문] Attention Is All You Need, 2017개발/머신러닝-딥러닝 2022. 6. 13. 23:22
제가 이해한 내용을 정리한 글입니다. 오류가 있으면 고쳐주세요!
앞서 소개했던 BERT의 근본이 되는 방법인 Transformer를 소개하는 논문이다.
트랜스포머 계열은 자연어 처리 뿐만 아니라 여러 데이터에서 사용되는데,
Vision 분야의 ViT, 시계열 분석의 TFT 등이 있다.
배경
RNN계열의 모델은 시퀀스 모델링이나, 언어모델, 기계번역과 같은 분야에서 SOTA를 달성해왔다.
그러나 RNN 모델은 hidden states에서는 $h_t$를 계산하기 위해서 $h_{t-1}$이 반드시 필요한 재귀형(혹은 순차적) 모델이므로 병렬화할수 없었다.
이로 인해 메모리 제약이 걸리고, 학습과정에서 batch에 제한이 생겨 긴 시퀀스를 학습하는 것이 힘들었다.
어텐션 구조는 입출력 시퀀스의 거리에 상관없이 dependency를 학습하게 하면서, 대부분의 RNN계열 NLP모델을 보조하는데에 사용되었다.
Transformer는 어텐션으로만 이루어진 모델로써, 입출력 문장을 global하게 학습할 수 있고, 더 병렬적인 학습이 가능하다.
기존에 순차적인 계산을 줄이기 위해서
입출력의 히든층을 병렬적으로 구성했고, Convolutional한 방법들이 사용되었는데,
입출력의 임의의 두 위치(임의의 두 단어)간의 관계를 계산하는 것이 어려워졌다.
Transformer 구조는 계산 시간을 상수시간까지 줄였다.
시퀀스의 의미를 계산하기 위해 시퀀스 내부의 각 포지션끼리 관계를 짓는 Self-attention은 많은 task에서 잘 사용된다.
End-to-end 메모리 네트워크는 recurrent attention 방법을 기반으로 하고, QA와 언어 모델에서 높은 성능을 보였다.
모델
기본적으로 시퀀스 변환 모델은 인코더 - 디코더 구조를 따른다.
인코더는 입력 시퀀스$X = (x_1, x_2, ...)$를 $Z = (z_1, z_2, ...)$에 매핑시키고,
디코더는 Z를 이용해 출력 시퀀스 $Y = (y_1, y_2, ...)$를 auto-regressive하게 생성한다.
트랜스포머도 셀프어텐션과 FC만으로 구성된 인코더 - 디코더 구조를 가진다.
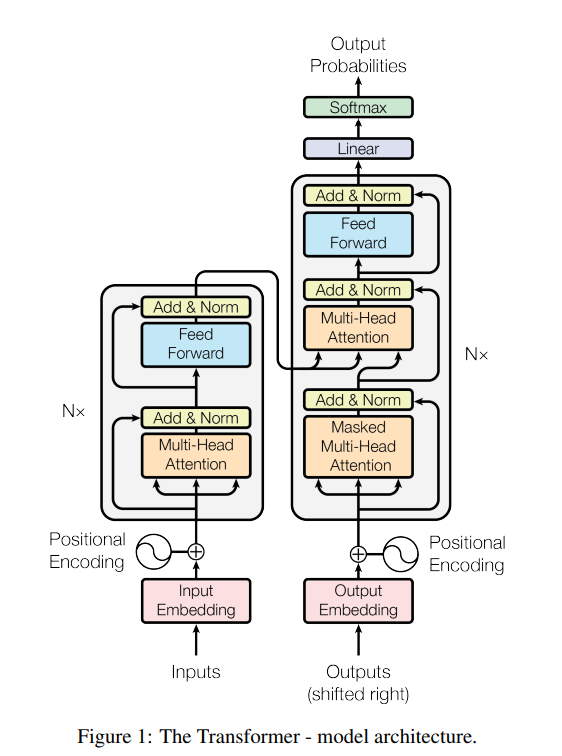
위 그림으로 설명하자면 인코더는 N(=6)개의 레이어로 구성되어 있고,
각 레이어에는 Multi-Head Self-Attention층과 feed-forward의 sub-layer로 구성되어 있다.
각 서브레이어에는 residual-connection을 적용하며, normalization을 진행한다.
이 계산을 편하게 하기 위해서 모든 output은 $d_model = 512$로 동일하게 구성했다.
디코더도 N개의 레이어로 구성되어 있으며, 각 디코더의 서브레이어는 인코더의 출력을 받는 멀티 헤드 셀프 어텐션 레이어를 추가해서 세 개의 서브 레이어가 있다.
디코더의 셀프 어텐션 레이어는 인코더의 것과는 달리 한 시퀀스의 모든 위치에서 관계를 정의 하는 것이 아니라
특정 포지션을 기준으로 과거 포지션만을 이용해서 해당 포지션의 의미를 결정하도록 수정했다.
어텐션
어텐션은 Query, Key, Value를 이용해 Output을 만드는 것이다.
어텐션 함수는 additive attention과 dot-product attention이 있는데,
dot-product attention이 더 빠르고, 공간 효율적이라 채택했다.

Q, K, V는 입력 X에 $W^Q$, $W^K$, $W^V$를 곱한 것이다. 이 W들은 모델이 학습해야 할 파라미터 행렬이다.
이렇게 계산한 Q, K, V를 이용해 각 단어의 의미를 구체화 하는데, 과정은 다음과 같다.
- $QK^T$를 계산한다.
- $Q$의 i번째 행과 $K^T$의 j번째 열의 곱이 입력 문장에서 j번째 단어가 i번째 단어에 미치는 영향 점수이다.
- $QK^T$를 K벡터 차원의 루트값($\sqrt{d_k}=8$)으로 나누어 준다(Scale). 이는 $d_k$가 커질수록 softmax적용시에 기울기 값을 보정해주기 위함이다.
- 이렇게 scaling 된 값을 softmax를 취해서 하나의 i에 대해서 모든 j의 영향력 비율을 만들어준다.
- 이 영향력 행렬(Attention Matrix)과 V행렬을 곱하면 모든 i, j에 대해서 j의 i에 대한 의미 가중치가 만들어지고, 하나의 i에 대해서 모든 j를 더해주면 i의 의미 벡터가 재정의 된다($Z = (z_1, z_2, ..., z_i, ...)$).
멀티 헤드 어텐션
위 과정은 하나의 어텐션에서 일어나는 과정이고, 이를 병렬적으로 수행하는 것이 더 좋다고 한다.
그 이유는 한 단어에 대해서 헤드별로 각각 다른 위치에서 의미를 담을 수 있기 때문이다(일종의 앙상블).
멀티 헤드 어텐션 $d_model = 512$의 차원을 가진 Q, K, V를 사용하는 것이 아니라 $d_q = d_k$, $d_v$차원을 가진 어텐션 $h$개를 병렬적으로 계산하여 output을 얻는다.
이 output을 수평적으로 concat하고 선형 함수를 거친 뒤 결과 값을 만든다.
Transformer에서 attention의 종류
- Encoder-decoder attention: query는 이전 디코더의 것을 사용하고, key, value는 encoder의 output을 사용한다. 이는 디코더의 모든 위치에서 입력 시퀀스 전체를 참조할 수 있도록 한다.
- Self-attention in encoder: 이전 encoder의 출력에서 q, k, v를 만든다. 인코더 층에서 시퀀스의 한 단어는 이전 인코더 층의 모든 단어와 관계를 참조할 수 있다.
- Self-attention in decoder: 디코더 층에서는 올바른 auto-regressive 추론을 위해서 오-왼 방향의 흐름을 막아야 한다. 이를 위해서 미래의 값들을 scale과정에서 $-∞$로 마스킹해 해당 흐름을 막았다.
position-wise FeedForward Net
어텐션 층 이후에 2개의 FC와 ReLU가 있는 피드 포워드 층을 지난다.
이를 통과할 때는 각 단어들이 독립적으로 통과하며 해당 층에서는 파라미터를 공유한다.
임베딩과 Softmax
디코더의 결과를 $d_model$로 변환하기 위해 선형함수와 softmax함수를 사용한다.
softmax의 결과는 각 단어별로 다음에 나올 확률이며, 가장 높은 확률을 갖는 단어를 출력한다.
포지션 인코딩
시퀀스의 단어 순서를 정하는 방법이 없으므로, 포지션 인코딩을 따로 진행한다.
학습을 활용하거나 함수를 활용하는 다양한 방법이 있는데,
논문에서는 다른 주파수를 갖는 코사인 함수를 사용했다.
Why Self-Attention?
self-attention과 RNN계열, CNN계열을 비교해보자.

- 계산속도
- 계산을 병렬화 할 수 있다.
- 입출력 단어간 최대 거리
self-attention은 모든 경우에서 좋은 성능을 보였다.
또한 각의 층에서 단어들간의 관계를 softmax로 수치화하여 계산하므로 모델의 해석도 쉬워진다.
결론
번역 분야에서 RNN or CNN계열의 모델보다 빨랐으며, 영-독 번역, 영-불 번역에서 SOTA를 달성했다.
코드
Pytorch로 sublayer → layer → model로 나누어 구현한 코드가 있어서 첨부합니다.
https://github.com/jadore801120/attention-is-all-you-need-pytorch/tree/master/transformer
GitHub - jadore801120/attention-is-all-you-need-pytorch: A PyTorch implementation of the Transformer model in "Attention is All
A PyTorch implementation of the Transformer model in "Attention is All You Need". - GitHub - jadore801120/attention-is-all-you-need-pytorch: A PyTorch implementation of the Transformer mo...
github.com
'개발 > 머신러닝-딥러닝' 카테고리의 다른 글
[논문] BERT, 2018 (0) 2022.06.09 [논문] - A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music, 2018 (0) 2022.06.08 [DACON] 한국어 문장 관계 분류 w/KoBART (3) 2022.06.02 [논문] CNN - AlexNet, 2012 (0) 2022.03.08 [Kaggle] Titanic - Machine Learning from Disaster (0) 2022.01.23 - $QK^T$를 계산한다.