-
[DACON] 한국어 문장 관계 분류 w/KoBART개발/머신러닝-딥러닝 2022. 6. 2. 11:31
DACON 대회
한국어 문장 관계 분류 경진대회 - DACON
좋아요는 1분 내에 한 번만 클릭 할 수 있습니다.
dacon.io
KoBART를 이용한 한국어문장 학습을 공부하다가 실습하면서 해보면 좋을 것 같아서 선정했다.
코드공유란의 아래 코드를 참고해서 작성했다
Hugging Face를 활용한 Modeling(public: 0.841)
한국어 문장 관계 분류 경진대회
dacon.io
0. 목표
문장1과 문장2의 관계에 대해서 정확하게 분류하는 것.
Label은 참, 거짓, 중립이 있다.
1. 데이터 확인
Train_set에는 문장 두 개와 label이 있으며, Test_set에는 문장 두개가 있다.

Train_set에는 약 25000개의 데이터가 존재한다.

2. 데이터 처리


데이터에서 한글과 숫자만 남겼으며,
문장1과 문장2를 <unused0>토큰을 사이에 두고 합쳤다. (kobart에서는 0~99까지의 unused 토큰이 존재)
문장의 시작 과 끝을 알리는 토큰이 없으면 학습과정에서 오류가 발생하기 때문에 추가해주었다.
3. 모델
Huggingface에 올라온 KoBART를 사용
KoBART의 분류모델은 기본적으로 긍정/부정의 2-Label 분류 모델이기 때문에
config수정을 통해 3-Label모델로 바꿔준다.

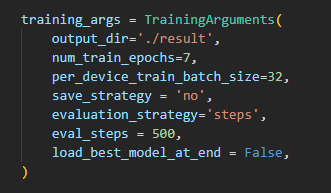
TrainingArgs의 경우 save_strategy를 'no'로 설정해야 한다.
Trainer에서 save하는 과정에서 tokenizer도 save하기 때문인데,
bart관련 모델에는 save_vocabulary가 구현 되어있지 않기 때문인 것 같다.
save옵션을 끄던가, tokenizer함수에서 save_vocabulary함수를 따로 구현해서 사용해야 할 것 같다.
save_pretrained() 에 NotImplemented Error 발생 · Issue #14 · SKT-AI/KoBART
안녕하세요. 먼저 좋은 모델을 공개해주셔서 감사합니다. 모델의 토크나이저를 사용하는 도중 에러가 발생하여 이슈를 남깁니다. 환경 Python 3.6.9 Transformers 4.3.3 torch 1.7.1+cu110 CUDA Version 11.2 KoBART 0
github.com
4. 결과

꽤.. 낮은 점수가 나왔다.
파라미터 튜닝이 필요할 것 같고, 전처리도 세심하게 해야할 것 같다.
전처리의 경우 문장들에 띄어쓰기가 제대로 되어 있지 않은 것을 발견했다.
kobart에서 사용하는 bpe 토크나이저의 경우 단어의 모양에 영향을 많이 받으므로 띄어쓰기를 적용할 필요가 있어보인다.
GitHub - haven-jeon/PyKoSpacing: Automatic Korean word spacing with Python
Automatic Korean word spacing with Python . Contribute to haven-jeon/PyKoSpacing development by creating an account on GitHub.
github.com
띄어쓰기 뿐만 아니라 맞춤법등의 문제도 있을 수 있을 것 같아, 맞춤법 교정기도 적용해볼 수 있을 것 같다.
GitHub - ssut/py-hanspell: 파이썬 한글 맞춤법 검사 라이브러리. (네이버 맞춤법 검사기 사용)
파이썬 한글 맞춤법 검사 라이브러리. (네이버 맞춤법 검사기 사용). Contribute to ssut/py-hanspell development by creating an account on GitHub.
github.com
'개발 > 머신러닝-딥러닝' 카테고리의 다른 글
[논문] Attention Is All You Need, 2017 (0) 2022.06.13 [논문] BERT, 2018 (0) 2022.06.09 [논문] - A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music, 2018 (0) 2022.06.08 [논문] CNN - AlexNet, 2012 (0) 2022.03.08 [Kaggle] Titanic - Machine Learning from Disaster (0) 2022.01.23