-
[프로젝트] 약 추천 서비스개발/프로젝트 2022. 6. 3. 12:29
GitHub - LJBang/Drug_Recommendation: 자연어 처리를 통한 약물 추천 챗봇
자연어 처리를 통한 약물 추천 챗봇. Contribute to LJBang/Drug_Recommendation development by creating an account on GitHub.
github.com
개요
UCI에서 제공하는 약과 그 리뷰에 대한 데이터셋을 기반으로 사용자가 증상을 입력하면 적절한 약을 추천해주는 프로젝트
적합한 약을 추천해주기 위해서 영어로 된 리뷰 데이터를 학습하여 condition을 분류하는 모델을 만들고,
해당하는 condition에서 rating의 평균이 가장 높은 약들을 추천한다.
서비스의 형태는 안드로이드를 이용한 챗봇이며, condition예측과 약 추천을 위한 Flask 서버 또한 구축했다.
데이터처리
기본적으로 오류값, NaN값 처리를 진행했다. 예를 들어 review 컬럼의 경우 작은 따옴표가 모두 깨져있었기 때문에 바꿔주었고, condition 컬럼의 경우 </span>태그가 붙은 잘못 된 값이 있었기 때문에 삭제해주었다.
다음으로는 유사 데이터들을 병합했다.
프로젝트 진행중 약을 살펴보는 과정에서 성분이 같으나 다른 제품인 경우(예를 들어, 타이레놀과 타세놀)가 많이 있어서 이를 모두 찾고 병합해주었다.
또한 condition의 경우에도 Depression과 Major Depressive Disorde와 같이 유사하지만 다르게 표현된 데이터들이 많이 있었고, 팀원들과 회의를 하며 적절히 병합했다.
우리가 구현한 모델은 약 복용자가 남긴 리뷰를 학습해 condition을 분류하는 일종의 분류 모델이었는데,
condition의 개수가 총 937개로 분류모델로 분류하기에는 많았다.
따라서 리뷰 개수를 기준으로 상위 50개를 뽑아서 위에서 말한 condition 병합 과정을 거친 뒤, 상위 20개를 선택하여 20개를 분류하는 모델을 구현하기로 했다.
임베딩
자연어 데이터를 분석하기 위해서는 단어의 의미를 뜻하는 임베딩 과정이 중요함을 알게 되었다.
우리 팀은 총 두 개의 방법을 사용했는데, Word2Vec을 이용한 임베딩과 BERT를 Fine-Tunning하는 임베딩 방법을 사용했다.
Word2Vec
첫 번째로 Word2Vec을 이용한 임베딩을 되짚어 본다면
Word2Vec은 주변 단어를 이용해 단어를 임베딩 하는 방법인데,
쉽게 말해서 유사한 문장에서 같은 위치에 있으면 비슷한 단어가 되도록 임베딩 하는 방법이다.
이는 주변 단어들을 고려하는 방법이긴 하지만 동음이의어를 표현할 수 없기에 문맥을 고려하지는 못한다.
우리는 Word2Vec을 이용해서 리뷰 데이터들을 임베딩 한 뒤에 이를 입력으로 condition을 분류하는 모델들을 구성했다.
XGBoost, MLP, LSTM, TEXT-CNN을 사용해서 각각 분류모델을 구성해봤고,
이 중에서 LSTM의 분류 성능이 가장 좋게 나왔다.
LSTM은 순서를 고려할 수 있는 모델이기 때문에 단어들의 입력 순서를 고려하여 모델이 학습되고,
이 때문에 성능이 좋게 나온 것이라 생각했다.
이 덕분에 자연어 문장을 처리할 때에는 순서, 즉 문맥이 중요하리라 생각할 수 있었고, 분류 과정에서 뿐만 아니라 임베딩과정에서부터 문맥을 고려할 수 있는 모델을 찾았다.
BERT
BERT는 Transformer 모델로서 어텐션 인코더를 활용해서 단어를 임베딩 하는 모델이다.
주변 단어들을 통해서 임베딩을 하는 것은 유사하지만, 같은 단어라도 주변 단어에 따라서 다르게 임베딩 되며,
단어의 입력 순서까지도 고려할 수 있는 모델이다.
BERT를 사용할 때는 Wiki등에서 대량의 문장을 통해 미리 학습한 Pretrained된 모델을 사용하였다.
우리가 사용하는 데이터보다 훨씬 큰 데이터로 학습되어 있기 때문에, 임베딩의 성능이 우수할 것이라 판단했고,
우리가 가진 데이터로 fine-tunning해서 사용할 경우 기존보다 더 좋은 분류 성능을 보일 것이라 생각했다.
분류기는 BERT에서 제공하는 분류기를 사용했고, 최종적으로 f1-score가 약 89%의 성능을 보였다.
서버
Flask를 이용해서 REST API 서버를 구축했다.
모델을 불러오는 py파일을 플라스크 앱에서 불러오고,
예측 결과를 안드로이드 클라이언트에게 제공하기 위해서 json형태로 데이터를 만들고 API를 제공했다.
모델이 condition을 예측하는데에 시간이 오래걸리지 않았기 때문에 바로바로 결과를 클라이언트에게 전달할 수 있었다.
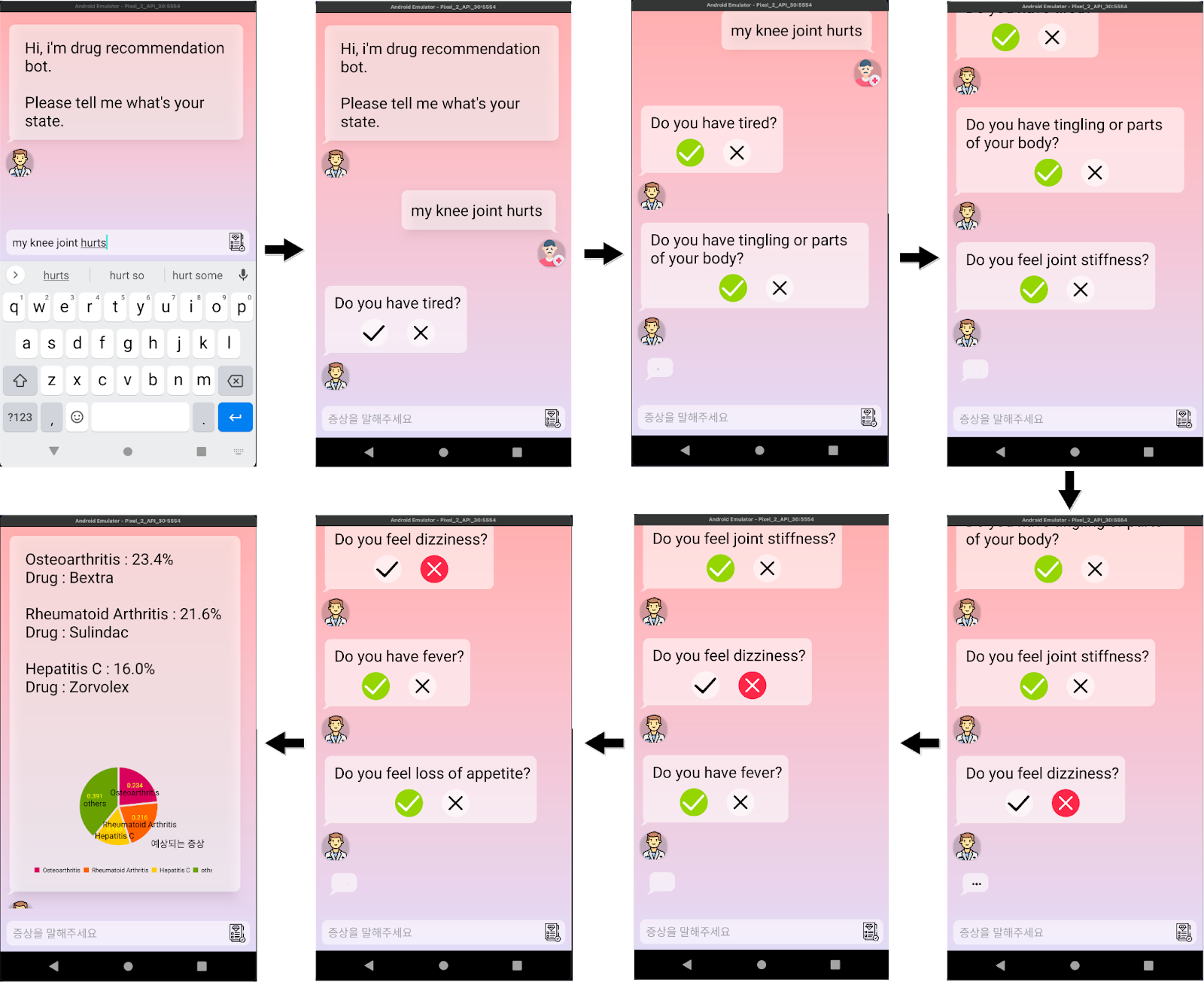
챗봇
챗봇형태로 만들기 위해서 다이얼로그 흐름을 만들었다.
- 가장 먼저 사용자에게 자유형식의 입력을 받는다. 이 입력은 사용자가 겪는 증상일 것이라 생각했다.
- 입력을 통해 모델이 condition을 예측한다.
- 예측한 결과 확률이 일정 수치(80%)를 넘지 않을 경우 다른 증상이 없는 지 물어본다.
- 결과 확률이 일정 수치를 넘을 경우 condition을 성공적으로 추론했다고 판단하고, 약을 추천해준다.
- 대화가 오래 지속될 경우(n회 이상) 사용자가 모든 증상을 입력했다고 판단하고 확률이 가장 높은 condition과 그에 따른 약을 추천한다.
문제점
여기서 큰 문제가 발견되었다.
우리가 사용한 데이터는 '약을 복용하고 난 후의 리뷰'였고,
서비스시에 사용자에게 입력받을 입력은 '사용자가 겪고 있는 증상'과 유사한 형태였기 때문이다.
두 입력의 성질은 분명히 다른 것이었고, 따라서 테스트 데이터 셋으로 89%의 성능이 나왔지만
실제 서비스 환경에서 임의로 만든 문장에 대해서 예측했을 경우 질병을 전혀 다르게 분류하는 경우가 많았다.
또 서비스에 대해서 문제가 있었는데,
챗봇 형태를 유지하기 위해서는 챗봇이 주도적으로 질문을 던지거나 최소한 어떤 대답을 해야하는 지 제공해야 하는데,
기존 형태는 전적으로 사용자가 자유롭게 쓴 입력을 바탕으로 예측을 하고,
필요에 따라서 그저 '다른 증상은 없나요?'라고 물어보는게 전부였다. 즉 챗봇의 티키타카가 안됐다.
해결책
이를 해결하기 위해서 질병을 높은 확률로 특정하기 전까지 다른 증상을 계속해서 입력받는 방법을 사용했으나,
해결할 수 없었고, 다른 방법을 찾아봐야 했다.
추가적인 데이터
가장 먼저 condition에 따른 증상을 구할 필요성을 느꼈다.
사용자의 입력에 직접적인 증상이 있다면 그 증상을 포함하는 condition의 예측 확률이 높아질 것이라 생각했다.
따라서 영국 국민 건강 서비스 포털을 활용해서 프로젝트에 사용할 condition 20개에 대한 증상데이터를 모으고, 테이블로 구성했다.
이 과정에서도 유사한 증상 데이터들을 합치는 과정을 거쳤다.
서비스 개선
위에서 모은 증상 데이터를 가지고 서비스의 시나리오를 발전시켰다.
이전처럼 '다른 증상은 없나요?'라고 물어보는 것이 아니라,
모델의 결과에 따라서 해당하는 condition의 대표적인 증상이 있는지를 질문하는 방식으로 바꾸었다.
이 질문에 대한 대답을 yes / no로 구성하여 특정 증상이 없다고 응답한 경우
그 증상을 포함하는 모든 질병의 확률을 줄이고 비율을 조정하는 방법으로 증상을 특정했다.
후기
가장 먼저 머신러닝 프로젝트에서 데이터의 중요성을 깨달은 프로젝트였다.
프로젝트의 방향과 데이터가 맞지 않았고, 이 때문에 추가적인 데이터를 수집하고, 시나리오를 새로 구축해야 했다.
설령 적합한 데이터를 사용했다고 하더라도, 동의어, 유의어와 같은 데이터를 어떻게 처리할 것인지를 고민하는 것이 중요함을 알 수 있었다. 이번 프로젝트의 경우에는 유사한 질병, 약들을 모두 합쳐서 학습에 사용할 데이터를 늘릴 수 있었다.
둘째로는 자연어처리 모델에 대해서 관심을 가지게 되었다.
데이터를 처리하는 과정에서 불용어, 단어의 원형 등을 어떻게 처리해야 하는가에 대해서 많이 찾아보았고,
여러 임베딩 방법들도 찾아보면서 단어의 의미를 어떻게 벡터화 하는지를 알 수 있었다.
특히 문장의 형태로 된 문서에서 단어의 순서가 의미를 표현하는 데에 중요한 요소임을 알게 되었다.
간단한 Word2Vec에서부터 BERT나 GPT와 같은 트랜스포머 모델에 대해서도 한 번 공부해보는 기간이었다.
셋째로는 ML모델의 서빙에 대해서도 생각해보았다.
이번 프로젝트에서는 Flask를 사용해서 모델을 불러오고, REST API형태로 안드로이드 클라이언트에게 제공하였다.
이번 프로젝트에서는 간단한 모델로 짧은 문장을 입력받아서 처리하였기 때문에 예측하는데 큰 시간이 걸리지 않았지만,
더 큰 모델을 사용하는 프로젝트에서는 어떤 방법으로 모델을 서빙하는지 궁금했다.
넷째로는 서버에 다중 접속 처리를 어떻게 할 것인가를 고민했다.
이번 프로젝트에서는 모델에 조금 집중하느라 구현하지는 않았지만 팀 내에서 다중 접속 처리를 어떻게 할 것인가에 대해서 말을 했었다.
지금 생각해보면 세션을 부여하거나, API 키를 부여하는 등의 방법이 있을 것이고, gunicorn과 같은 웹서버, wsgi등에서 worker를 나누어서 병렬처리하는 방법도 있을 것 같다.
'개발 > 프로젝트' 카테고리의 다른 글
[프로젝트] 해양 재난 상황판 (2) (0) 2022.03.01 [프로젝트] 해양 재난 상황판 (1) (0) 2022.02.10 [프로젝트] TradingBot / 업비트 자동 매매 봇 (0) 2022.01.18 [프로젝트] Django 프로젝트 / Heros (0) 2021.12.09